

Yapay zekâ dünyasında güç yarışı çoklukla daha büyük modeller üzerinden ilerler. Fakat Alibaba’nın yeni Qwen3.5 Small Model Series yaklaşımı bilakis çevirebilecek bir gelişmeyle gündemde. Yanıtılan yeni seri, sırf 16 gün içinde yayınlanan dokuz modelle süratli bir lansman sürecini tamamladı. Serinin en dikkat çeken tarafı ise küçük boyutuna karşın yüksek performans sunması.
Seride 0.8 milyar, 2 milyar, 4 milyar ve 9 milyar parametreye sahip dört ağır model bulunuyor. Bu modeller bilhassa dizüstü bilgisayarlar, edge aygıtlar ve tek GPU’lu sistemler için tasarlandı. En dikkat alımlı model ise Qwen3.5-9B. Yalnızca 9 milyar parametreye sahip olmasına karşın çok daha büyük modellerle rekabet edebiliyor. Bu da yapay zekâ uygulamalarını bulut altyapısından çıkarıp direkt lokal aygıtlara taşıma ihtimalini güçlendiriyor.
Seri sırf metin üretimiyle sonlu değil. Metin, görsel ve görüntü sürece yeteneklerini tıpkı mimaride birleştirerek çok modlu kullanım sunuyor. Ayrıyeten 201 lisanı kapsayan 248 bin sözlük geniş bir kelamlık yapısına sahip.
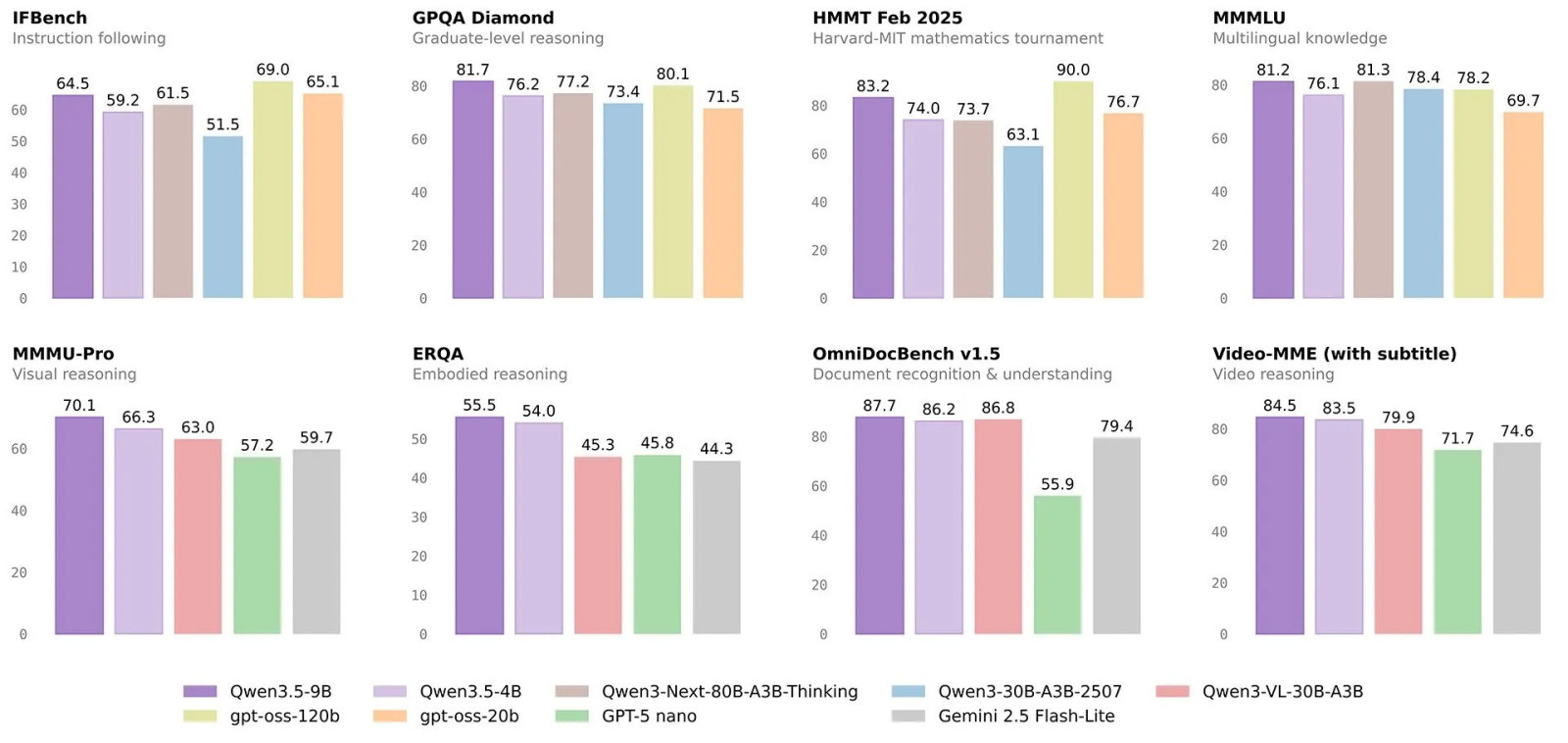
Dev modelleri zorlayan performans
Benchmark sonuçları Qwen3.5 serisinin neden bu kadar dikkat çektiğini net biçimde ortaya koyuyor. 9B modelinin performansı birtakım testlerde kendisinden üç kat büyük olan modelleri bile geride bırakıyor. Örneğin:
- MMLU-Pro testinde 82.5 puan
- GPQA Diamond testinde 81.7 puan
- LongBench v2 testinde 55.2 puan
Bu sonuçlar modelin evvelki jenerasyon Qwen3-30B modelini geçmesini sağlarken kimi alanlarda Qwen3-80B düzeyine yaklaşmasını da mümkün kılıyor.
Görsel manaya testlerinde de tablo dikkat cazibeli. MMMU-Pro benchmark’ında 9B modeli 70.1 puana ulaşarak kimi küçük ölçekli rakip modelleri açık biçimde geride bırakıyor. MathVision testinde ise 78.9 puan elde ediyor. 4B modelinin bile MMMU-Pro testinde 66.3 puan alması, küçük modellerin artık önemli bir performans düzeyine ulaştığını gösteriyor.
Açık kaynak stratejisi yapay zekâ yarışını değiştirebilir
Qwen3.5 serisini farklı kılan bir öbür öge ise büsbütün açık lisansla yayınlanması. Apache 2.0 lisansı sayesinde geliştiriciler modelleri özgürce kullanabiliyor ve yine eğitebiliyor. Modeller Hugging Face ve ModelScope üzerinden indirilebiliyor. Ayrıyeten vLLM, llama.cpp ve çeşitli quantization teknikleriyle uyumlu çalışıyor. Bu da düşük donanımlı sistemlerde bile kullanılmasını kolaylaştırıyor.
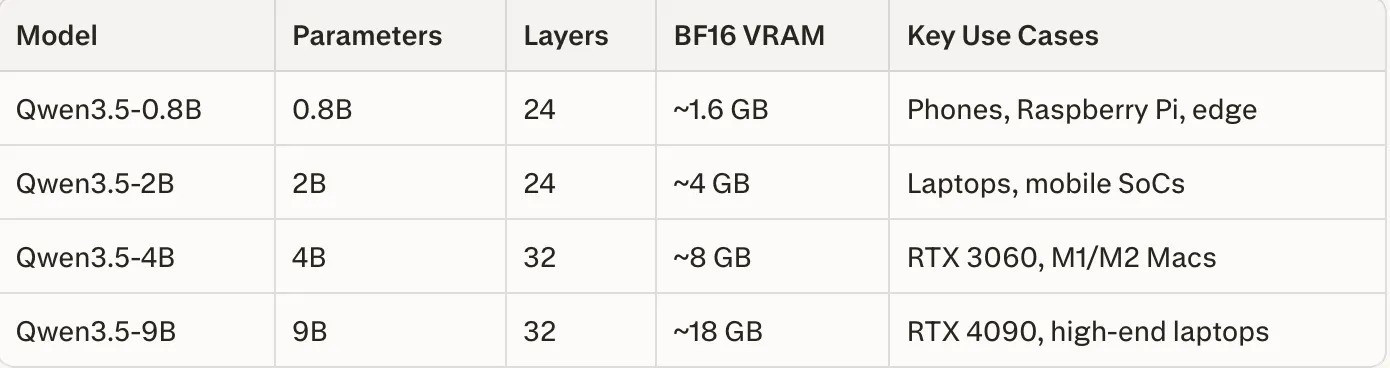
Teknik tarafta ise “Gated DeltaNet” ismi verilen hibrit bir dikkat düzeneği kullanılıyor. Bu yapı lineer ve tam dikkat katmanlarını bir ortaya getirerek hem performansı hem de verimliliği artırıyor. 262 bin tokenlık doğal bağlam uzunluğu ve 9B modelde 1 milyon tokene kadar genişletilebilen bağlam kapasitesi de uzun metinlerle çalışan uygulamalar için değerli bir avantaj sunuyor.
Küçük modellerin çağı yeni başlıyor
Yapay zekâ dünyası uzun müddettir devasa parametre sayılarına odaklanmış durumda. Fakat Qwen3.5 serisi küçük modellerin de büyük tesirler yaratabileceğini gösteriyor. Mahallî aygıtlarda çalışabilen güçlü yapay zekâ modelleri; kapalılık, maliyet ve sürat açısından büyük avantaj sağlıyor. Bu nedenle birçok uzman, önümüzdeki yıllarda “küçük ancak güçlü” modellerin teknoloji ekosisteminde çok daha yaygın hale geleceğini düşünüyor. Alibaba’nın Qwen3.5 atılımı ise bu dönüşümün en dikkat cazibeli örneklerinden biri olarak şimdiden yapay zekâ dünyasında büyük bir tartışma başlatmış durumda.




Bir yanıt yazın