

 Yapay zeka alanında son yıllarda kaydedilen süratli ilerlemeye karşın, aktüel üst düzey modellerin karmaşık ve sistemsiz gerçek dünya şartlarında hala kırılgan olduğu ortaya kondu. Çinli teknoloji devi Tencent tarafından yayımlanan yeni bir teknik makale, yapay zeka sistemlerinin bağlamdan öğrenme konusunda önemli sınırlamalar taşıdığını ve bu durumun pratik kullanımı direkt etkilediğini vurguluyor.
Yapay zeka alanında son yıllarda kaydedilen süratli ilerlemeye karşın, aktüel üst düzey modellerin karmaşık ve sistemsiz gerçek dünya şartlarında hala kırılgan olduğu ortaya kondu. Çinli teknoloji devi Tencent tarafından yayımlanan yeni bir teknik makale, yapay zeka sistemlerinin bağlamdan öğrenme konusunda önemli sınırlamalar taşıdığını ve bu durumun pratik kullanımı direkt etkilediğini vurguluyor. İnsanlar anında öğreniyor, modeller hatırlamaya çalışıyor
Araştırmacılar, gelecekte yapay zeka modellerinin denetimli ortamların dışına çıkabilmesi için “bağlam öğrenmenin” model dizaynının merkezine yerleştirilmesi gerektiğini savunuyor. Araştırmacılara nazaran mevcut sistemler, gerekli bilgilere erişebilmelerine karşın bağlamı gerçek formda yorumlayamadıkları için görevleri dengeli biçimde yerine getiremiyor.
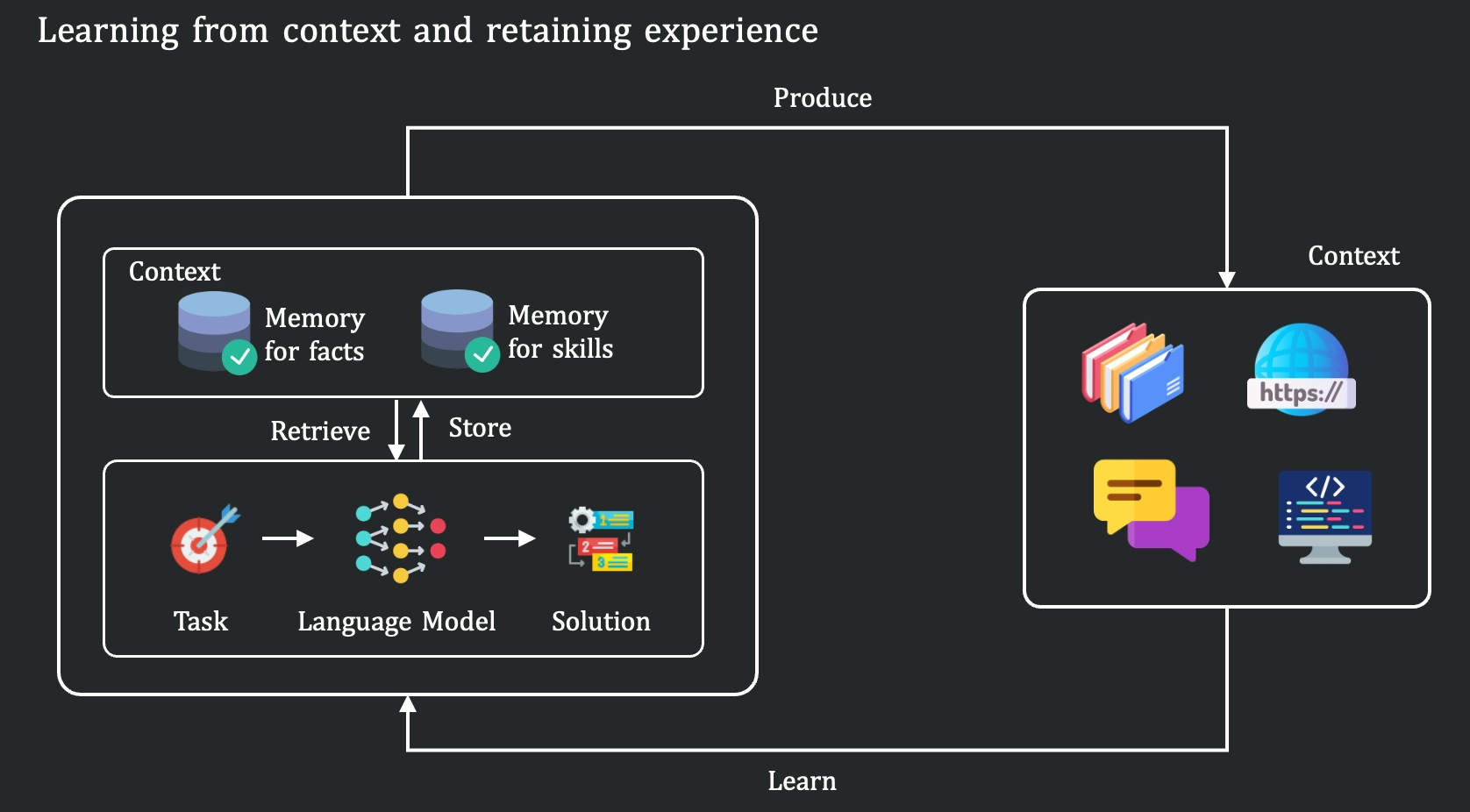 Çalışmada, beşerlerle yapay zekalar ortasındaki temel fark günlük örneklerle açıklanıyor. Bir yazılımcının daha evvel görmediği bir araç için dokümantasyonu süratle tarayıp kusur ayıklamaya başlaması, bir oyuncunun yeni bir oyunu kural kitabını okuyarak oynaya oynaya öğrenmesi ya da bir bilim beşerinin yüzlerce deney kaydını inceleyerek yeni bir alaka keşfetmesi bu farkın somut örnekleri olarak gösteriliyor.
Çalışmada, beşerlerle yapay zekalar ortasındaki temel fark günlük örneklerle açıklanıyor. Bir yazılımcının daha evvel görmediği bir araç için dokümantasyonu süratle tarayıp kusur ayıklamaya başlaması, bir oyuncunun yeni bir oyunu kural kitabını okuyarak oynaya oynaya öğrenmesi ya da bir bilim beşerinin yüzlerce deney kaydını inceleyerek yeni bir alaka keşfetmesi bu farkın somut örnekleri olarak gösteriliyor. Tencent’e nazaran insanlar bu süreçlerde geçmişte ezberlenmiş sabit bilgiye değil, o anda karşılarına çıkan bağlama dayanarak öğreniyor. Buna rağmen mevcut büyük lisan modelleri, yüklü olarak ön eğitim sırasında parametrelerine gömülmüş bilgiyi geri çağırıyor. Çıkarım basamağında ise yeni bilgiyi faal biçimde öğrenmek yerine, statik iç belleğine yaslanıyor.
Araştırmada bu durum, “yapısal bir uyumsuzluk” olarak tanımlanıyor. Modeller, bildikleri şeyler üzerinden akıl yürütmek için optimize edilmiş durumda. Meğer kullanıcılar, daima değişen ve dağınık bağlamlara bağlı sorunları çözebilen sistemlere gereksinim duyuyor.
Bağlam öğrenmeyi ölçmek için yeni standart geliştirildi
 Bu sorunu ölçmek emeliyle Tencent araştırma takımı, CL-bench ismi verilen yeni bir kıymetlendirme kriteri geliştirdi. Toplam 19 önde gelen yapay zeka modeli, 500 karmaşık bağlam, 1.899 misyon ve 31.607 doğrulama kriteri üzerinden test edildi. Bu misyonlar, modellerin “iş başında” öğrenme yeteneğini, yani verilen bağlamdan mana çıkararak yeni durumlara ahenk sağlama marifetini ölçmeyi hedefliyor.
Bu sorunu ölçmek emeliyle Tencent araştırma takımı, CL-bench ismi verilen yeni bir kıymetlendirme kriteri geliştirdi. Toplam 19 önde gelen yapay zeka modeli, 500 karmaşık bağlam, 1.899 misyon ve 31.607 doğrulama kriteri üzerinden test edildi. Bu misyonlar, modellerin “iş başında” öğrenme yeteneğini, yani verilen bağlamdan mana çıkararak yeni durumlara ahenk sağlama marifetini ölçmeyi hedefliyor. CL-bench, klasik bilgi sorularına dayanan kıyaslamalardan farklı olarak her misyonun kendi bağlamını modele sunuyor. Bu yaklaşım temelde insanların öğrenme biçimine daha yakın. Ek olarak bunu daima öğrenme modelleriyle de karıştırmamak gerek. Birisinde model, kendi yüklerini daima güncellerken bağlan öğrenmede temel parametreler değişmeden kalıyor.
Ortalama muvaffakiyet yüzde 17
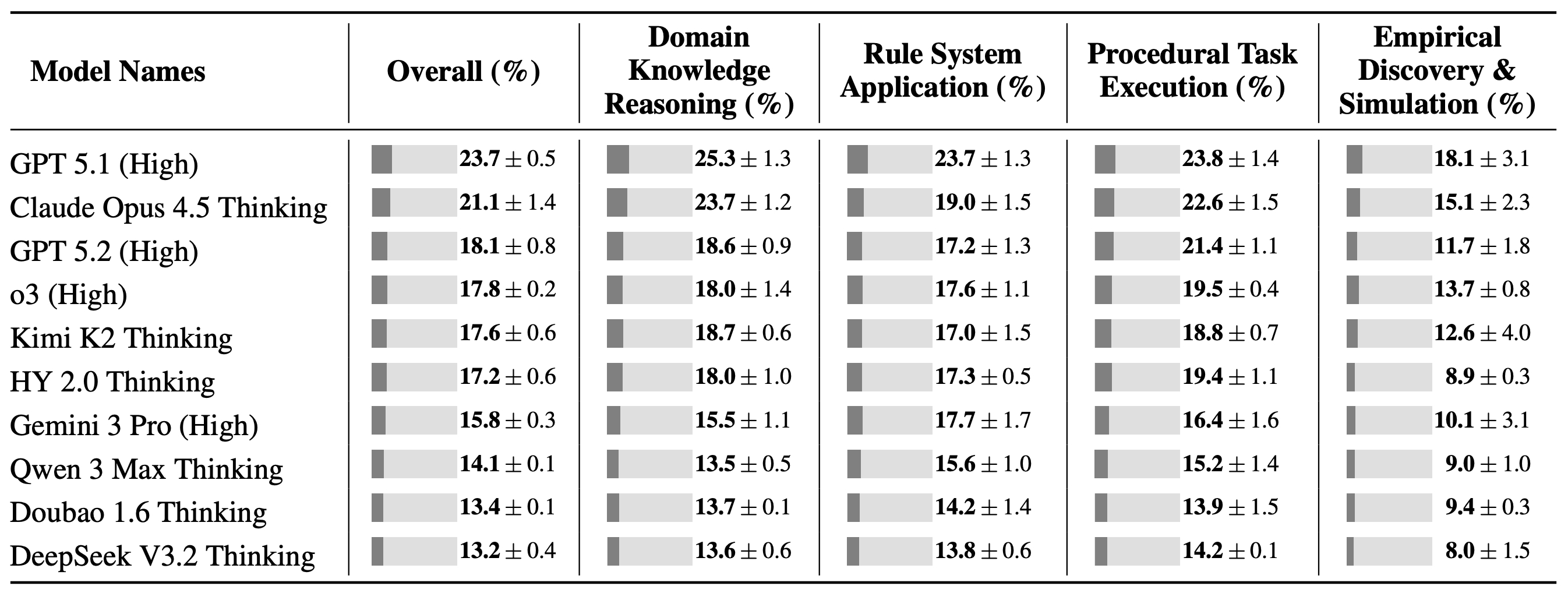 Test sonuçları ise yapay zekaların gerçek dünya karmaşıklığında nasıl da kaybolduğunu net biçimde ortaya koyuyor. Çünkü birinci 10 sıradaki modellerin CL-bench üzerindeki ortalama başarısı sadece yüzde 17,2 olarak ölçüldü. Çalışmada, şimdiki modellerin şimdi muteber bağlam öğreniciler olmaktan uzak olduğu vurgulanıyor.
Test sonuçları ise yapay zekaların gerçek dünya karmaşıklığında nasıl da kaybolduğunu net biçimde ortaya koyuyor. Çünkü birinci 10 sıradaki modellerin CL-bench üzerindeki ortalama başarısı sadece yüzde 17,2 olarak ölçüldü. Çalışmada, şimdiki modellerin şimdi muteber bağlam öğreniciler olmaktan uzak olduğu vurgulanıyor. Öte yandan en yüksek puanı yüzde 23,7 ile OpenAI’ın GPT-5.1 modeli alırken, onu yüzde 21,1 ile Anthropic’in Claude Opus 4.5 modeli izledi. Çin merkezli modeller ortasında en uygun performans, Moonshot AI’ın Kimi K2 modeliyle beşinci sırada ve yüzde 17,6 düzeyinde gerçekleşti. Tencent’in kendi modeli Hunyuan 2.0, yüzde 17,2 skorla altıncı sırada yer aldı.
Ancak üstte saydıklarımız “iyi” istatistikler. En başarılı olan GPT-5.1 modeli bile hiçbir bağlam verilmediğinde vazifelerin yüzde 1’inden daha azını çözebildi.
Araştırma, bağlam öğrenmenin gelişmesi halinde insan-yapay zeka bağının de değişeceğini öngörüyor. Buna nazaran beşerler, modele data sağlayan aktörler olmaktan çıkıp, en hakikat ve varlıklı bağlamı tasarlayan “bağlam sağlayıcılara” dönüşebilir.
Ancak burada kritik bir sorun var. Tencent’e nazaran bağlam öğrenme süreksiz bir süreç. Model, bağlam penceresi kapandığında öğrendiklerini unutuyor. Asıl büyük soru ise şu: Bağlamdan edinilen bilgi nasıl kalıcı hale getirilebilir? Bu sırf olguları değil, hünerleri, tecrübesi ve kalıpları da kapsayan daha derin bir öğrenme manasına geliyor.
Bu ortada CL-Bench’e GitHub yahut Hugging Face ulaşabilirsiniz.




Bir yanıt yazın